From school, training, and work, we'll get deeper knowledge in software development. It's not uncommon we lack investment education since schools don't teach everyone, unless we happen to be in the related majors. I decide to write something about investment to reflect what I've learned by myself so far.
Financial advisor
A Financial advisor is a person that provides financial advice or guidance to clients. They can be insurance agents, investment managers, tax advisors, real estate planners, etc. Investment managers deal with their clients' investment portfolios. It may be good to have your money managed by experts. But you have to be cautious in choosing a financial advisor. They will charge you fees for compensations. Some charges 1% - 1.5% of the assets they manage. Some charge by hour. Regardless your criteria, please add this: a fiduciary. A fiduciary has a higher ethical standard and is required to act on behalf of his or her clients benefits. That means, if the client had all the prerequisites and the information, the client would have taken the same action. A non-fiduciary is only required to make suitable and reasonable action, which may not be the client's best benefits.
Actively managed fund and passively managed fund
An actively managed fund is always attended by a manager, who is supposed to be an expert. They pick the stocks, bonds and other investment vehicles in the funds. A passively managed fund, on the other hand, doesn't requires a fund manager to pick for the funds. They usually match the index they follow. With less human intervening, it incurs less fees to manage the fund.
You may believe actively managed fund will perform well, since an expert always keeps an eye on it and adjusts immediately to the market change. You remember the chart of the fund always looks good. For example in the screenshot, FSPTX outperforms the benchmark. (Note the chart is for illustration only. It doesn't mean the fund is good or bad). Is that the whole story? Do you notice the text below it? The performance data featured represents past performance, which is not guarantee of future results.
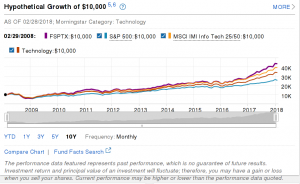
from https://fundresearch.fidelity.com/mutual-funds/summary/316390202
This study by S&P Down Jones Indices in 2016 shows that 90 percent of actively managed funds fail to outperform their index targets over the past one-year, five-year and 10-year periods. Why don't you find such funds from your fund managers? The funds can be discontinued. Fund managers don't want you to lose confidence.
One major factor in the under performance is the fee in actively managed funds. The cost can be the management fee, trading commission, etc. All financial advisers need compensations. It doesn't matter how well the fund performs. What really matters is how much you get after the fees. Let's look at the fee of the fund FSPTX.
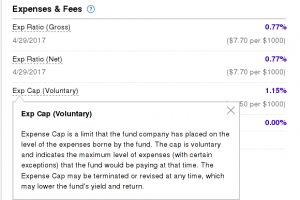
from https://fundresearch.fidelity.com/mutual-funds/fees-and-prices/316390202
Its expense ratio is 0.77% and its Exp Cap (Voluntary) is 1.15%. The expense ratio is what you pay right now. Exp Cap is the limit of the fee you may pay in future, which means you might end up paying 1.15% fee. For example, you have $10000 in investment and the market value doesn't change in 10 years. If the expense ratio at 0.77%, you pay $10000 * 10 * 0.77% = $770, If the expense ratio is 1.15%, you pay $10000 * 10 * 1.15% = $1150. That's $380 more for $10000, even when you don't have any gains. The fee of a passively managed fund can be lower than 0.1%. I'm sure you see the difference. If you worry about the fee, you may be scared when you know Expense Cap may be terminated or revised at any time. You don't have control how much you're charged.
First, most funds cannot outperform the index. You already don't have too many gains. Second, you need to pay more in fees to have an actively managed fund. Passively managed fund most likely just mirror the index it's tracking. It doesn't requires too many fees to get similar performance as an index. An actively managed fund needs perform much better than a passively managed fund to give you the equal gains, after you pay the fees. Those make passively managed fund more attractive than actively managed fund.
Diversification and re-balance
Don't put all eggs in one basket. For example, if you only invest in one company's stock, your return of investment is the same as the company stock. When the company has a rough year, or even goes bankruptcy, you may lose everything. The best way to reduce the risk is to diversify. You can diversify within the same category. For example, you buy 25 – 30 unrelated stocks. Or you can diversify across all categories. You have everything in your portfolio: stocks, bonds, precious metal, etc. The theory is that the same economy data won't affect all of them in the same way. It may hit one stock or one category heavily but be neutral or good for another one. In the end the positive smooths out the negative. You'll need to decide how to allocate your investment, depending on you risk tolerance and investment goal.
What strikes me is re-balance. It has a twofold effect. First, it shields you from more risks. Second, it is a simple way to buy at the bottom/sell at the top. For example, you have a portfolio with 80% stocks and 20% bonds. If the stocks grow to 90%. That may mean the stock is going up. Because it has a cycle, it'll going down some day. If you keep investing in stocks and the stock market crashes, you'll lose a lot. Why not re-balance and have more in bonds? You may sell some stocks and buy more bonds, or invest more in the bonds. In the end, you will have 80% in stocks and 20% in bonds. That may not be the top when you sell the stock. But who knows. Don't try to time the market. You're reducing the risks and having some gains.
Few can guarantee you can get in in and out of the market at the right time. But there are many ways to reduce the risks. Diversification and re-balance are good tools in your risks management.
Lump-sum vs recurring
Do you save the money until it's large enough before you investment? Or do you set aside smaller money in your paycheck and invest every month? The first approach is lump sum and the second one is recurring.
They both have advantages and disadvantages. For lump sum, if you buy when the market is at the bottom, you'll get much larger gains. Every rise will count as your gains afterwards. Remember to sell them at the right time too. You need much luck in both time. If the market crashes after you buy, you need to wait a long time before getting even. The second, regardless how the market is, you keep investing even with smaller money. For some money, you may lose. For some other money, you get gains. When you spread out investment like this, you're also reducing the risks. Lump sum can give you much higher return when you do that at the right time. Recurring on the other hand, can reduce your risks of timing the market wrong.
I've been talking most about avoiding the fees and reducing the risks. What really makes it works is discipline. Once you decide how to allocate your investment, how to re-balance, and whether lump-sum or recurring, don't let good or bad news in the market sway you. You need to research and analyze before you make any changes. Try to do it rationally, not emotionally. The best way to get more gains is to time the market right. That's almost impossible. Luck is much more important than expertise. The second best way is to reduce risks. Make sure you don't lose money before you get gains.